一、JAVA
基础
基本数据类型
•布尔型:boolean •整数型:byte、short、int、long •浮点型:float、double •字符型:char
数据结构
数组(Arrays) 数组(Arrays)是一种基本的数据结构,可以存储固定大小的相同类型的元素。 特点: 固定大小,存储相同类型的元素。 优点: 随机访问元素效率高。 缺点: 大小固定,插入和删除元素相对较慢。
列表(Lists) Java 提供了多种列表实现,如 ArrayList 和 LinkedList。
ArrayList: 特点: 动态数组,可变大小。 优点: 高效的随机访问和快速尾部插入。 缺点: 中间插入和删除相对较慢。
LinkedList: 特点: 双向链表,元素之间通过指针连接。 优点: 插入和删除元素高效,迭代器性能好。 缺点: 随机访问相对较慢。
集合(Sets) 集合(Sets)用于存储不重复的元素,常见的实现有 HashSet 和 TreeSet。
HashSet: 特点: 无序集合,基于HashMap实现。 优点: 高效的查找和插入操作。 缺点: 不保证顺序。
TreeSet: 特点:TreeSet 是有序集合,底层基于红黑树实现,不允许重复元素。 优点: 提供自动排序功能,适用于需要按顺序存储元素的场景。 缺点: 性能相对较差,不允许插入 null 元素。
映射(Maps) 映射(Maps)用于存储键值对,常见的实现有 HashMap 和 TreeMap。
HashMap: 特点: 基于哈希表实现的键值对存储结构。 优点: 高效的查找、插入和删除操作。 缺点: 无序,不保证顺序。
TreeMap: 特点: 基于红黑树实现的有序键值对存储结构。 优点: 有序,支持按照键的顺序遍历。 缺点: 插入和删除相对较慢。
栈(Stack) 栈(Stack)是一种线性数据结构,它按照后进先出(Last In, First Out,LIFO)的原则管理元素。在栈中,新元素被添加到栈的顶部,而只能从栈的顶部移除元素。这就意味着最后添加的元素是第一个被移除的。
Stack 类: 特点: 代表一个栈,通常按照后进先出(LIFO)的顺序操作元素。
队列(Queue) 队列(Queue)遵循先进先出(FIFO)原则,常见的实现有 LinkedList 和 PriorityQueue。 Queue 接口: 特点: 代表一个队列,通常按照先进先出(FIFO)的顺序操作元素。 实现类: LinkedList, PriorityQueue, ArrayDeque。
堆(Heap) 堆(Heap)优先队列的基础,可以实现最大堆和最小堆。
树(Trees) Java 提供了 TreeNode 类型,可以用于构建二叉树等数据结构。
字符串
String直接创建的字符串存储在公共池中,而 new 创建的字符串对象在堆上。
StringBuffer 和 StringBuilder(线程不安全)。
重写(Override)/重载(Overload)
重写(Override)是指子类定义了一个与其父类中具有相同名称、参数列表和返回类型的方法,并且子类方法的实现覆盖了父类方法的实现。 即外壳不变,核心重写!
重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。 每个重载的方法(或者构造函数)都必须有一个独一无二的参数类型列表。
集合
JAVA集合图解
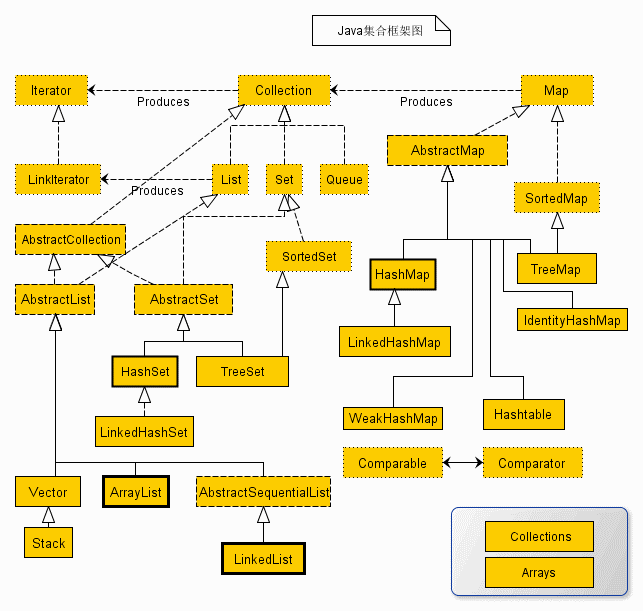
常用集合说明
ArrayList/LinkedList
ArrayList底层是数组,增删慢,查找快,需要连续内存。 LinkedList底层是双向链表,增删快,查找慢。
HashMap/HashTable
HashMap 和 HashTable 都是 Map 接口的实现类 。HashMap 采用数组、链表和红黑树的数据结构,非线程安全且无序,查找效率高,初始化默认容量为 2^4,每次扩容为原来的 2 倍;而 HashTable 采用数组和链表的数据结构,线程安全,键值均不允许为 null,默认初始大小为 11,每次扩充为原来的 2n+1。
多线程
线程状态如图
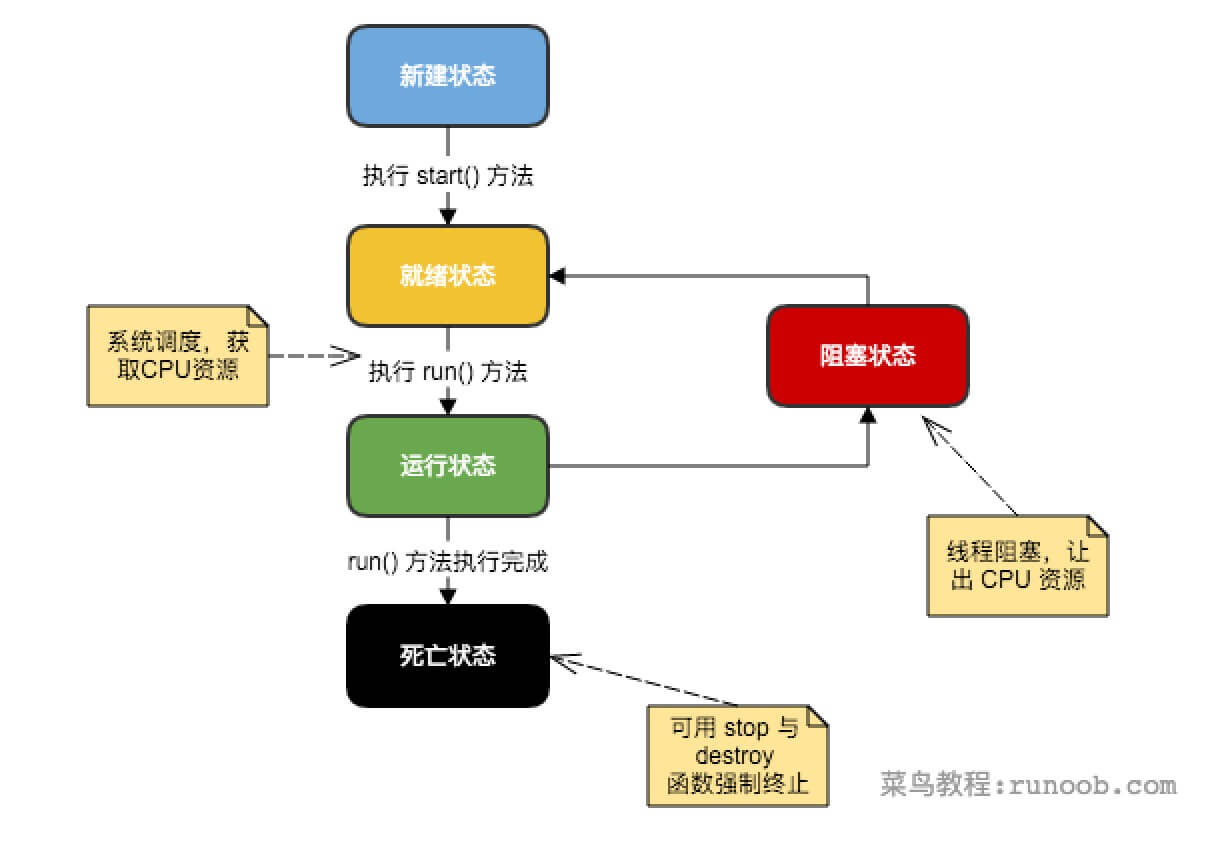
在java中一共有四种常见的创建方式,分别是:继承Thread类、实现runnable接口、实现Callable接口、线程池创建线程。
创建线程的runable和callble区别 Runnable 接口run方法没有返回值;Callable接口call方法有返回值,是个泛型,和Future、FutureTask配合可以用来获取异步执行的结果
Callalbe接口支持返回执行结果,需要调用FutureTask.get()得到,此方法会阻塞主进程的继续往下执行,如果不调用不会阻塞。 Callable接口的call()方法允许抛出异常;
而Runnable接口的run()方法的异常只能在内部消化,不能继续上抛(向上抛异常就是throws exception,内部消化指的是可以用try catch)
notify()和notifyAll()方法 notifyAll:唤醒所有wait的线程 notify:只随机唤醒一个 wait 线程
wait和sleep方法 wait()方法释放锁,等通知执行;sleep()方法 ,不释放锁等执行
**synchronized ** 采用互斥的方式,让同一时刻至多只有一个线程能持有【对象锁】
常用框架
springboot/hibernate/mybatis/mybatisplus 微服务组件:
- Spring Cloud Netflix:基于Netflix OSS(如Eureka, Zuul, Ribbon)的服务发现和路由。
- Spring Cloud Gateway:用于API网关的路由和过滤。
- Spring Cloud Config:用于管理分布式系统的配置。
- Spring Cloud Sleuth:用于日志收集和分布式追踪。
- Spring Cloud OpenFeign:声明式的Web服务客户端,使得调用远程服务更加简单。
- Prometheus和Grafana:用于监控微服务的性能和健康状态。
- ELK Stack(Elasticsearch, Logstash, Kibana):用于日志的收集、分析和可视化
数据库
mysql/oracle/PGsql/ES/崖山DB... sql执行步骤
- 连接器:建立连接并验证权限
- 分析器:进行词法分析和语法分析,构建语法树
- 预处理器:检查表/列存在性、验证权限、展开视图
- 优化器:进行逻辑优化和物理优化,生成最优执行计划
- 执行器:根据执行计划调用存储引擎接口执行查询
优化心得
-
索引优化 针对性创建索引,定时审视索引情况,避免索引失效。
-
查询语句优化
- 只选择必要列:避免使用SELECT *
- 使用limit限制返回行数
- 优化连接与子查询:使用JOIN替代子查询;使用EXISTS替代IN
- 在WHERE子句中避免导致索引失效的操作,如对字段进行NULL值判断、表达式计算或使用负向查询条件(!=、NOT IN等)避免全表扫描。
- GROUP BY前用WHERE过滤:减少分组处理的数据量
- 尽量避免GROUP BY
- 使用批量操作,减少事务开销。
- 正确应用索引左前原则
- 执行计划优化 使用EXPLAIN,分析执行计划 oracle可以在执行sql的时候可以干预执行计划
中间件
kafka、activeMQ、MQS
job/第三方
xx-job/LTS/SchedulerX... 流计算...
缓存
redis/MongoDB
负载
nginx
- 轮旋
- 最小连接
- IP HASH
- 随机
- 权重
其他
jenkins、Git、maven、docker、k8s...
监控工具:skywalking
开发流程工具:TFS/禅道/云龙...